Every claim,
with the numbers behind it.
An 11-section operator pack for investors who want to look under the hood — the model, the math, the build, and the cap table.
₹6 Cr buys 13 months to ₹4.2 Cr ARR.
The plan below is the baseline. Drag the sliders to test scenarios — the chart and KPIs update live.
₹0.3L → ₹13.4L over 13 months.
Sub ₹499 · Interview ₹199 · Cohort ₹18K · Mentorship ₹9K. Blended ARPU ₹460 → ₹780 by M12.
Creator network + campus through M6. Paid opens M6+ once funnel proven, drops to ~30% by M12.
CAC ₹250 · ARPU ₹780 · GM 81% · Payback 4 months at M12. AI cost curve owns the GM lift.
How we get the first 1,500 paying users in 12 months.
Layered channel strategy — warm, high-intent, low-CAC audiences first. Paid only opens once the funnel is proven. Click through the milestones below to see how the mix shifts month-by-month.
Campus wedge
DJ Sanghvi + IIT-B hackathon partnership already live. Scale to 20 campuses in Year 1 via student-ambassador program.
Creator-led demand
Each Anchor brings their existing audience. Core creators build on ScaleUp. Rev-share aligned so creators promote the platform, not just their session.
Community + content
LinkedIn + YouTube organic — weekly "outcomes, not content" thought leadership from founder + creators. Lowers CAC before paid kicks in.
Performance paid
Meta + YouTube after organic baseline. Target: <₹500 CAC per paying sub on paid alone. Blended CAC drops to ₹250 by M12.
What's already live, and what funding unlocks.
The platform is operational today — 5 tracks, full AI personalization stack, creator tools all shipped. Funding accelerates creator onboarding, vertical expansion, and the high-ARPU monetization layers. Click any phase below to drill in.
Already live, AI-graded, before a single rupee raised
The platform is operational on iOS + Android. We are raising to scale the creator network and GTM — not to build the product.
- 5 tracks live in beta — Product Management, Entrepreneurship, AI, Coding, and early Personal Finance + Soft Skills
- Track content currently aggregated from YouTube — to be replaced with creator-led original content post-funding
- 6-dimension AI-graded Coding Capstones — mobile-laptop hand-off, anti-cheat preflight, e2b sandbox, voice reflection re-grader
- Compass — unified AI coach with weekly/monthly/topic-scoped modes, replacing per-feature AI surfaces
- Coding Drills + adaptive mastery axes — prompting, debugging, decomposition, refactoring
- AI Mock Interview — voice-first on iOS (OpenAI Realtime) and Android (Whisper + GPT-4o + TTS)
- Adaptive Knowledge Profile + Readiness Score — updated by every interaction; daily personalised plan auto-seeded
- Notes upload + AI artifacts — auto-generated summary, flashcards, mind map, audio narration, quiz
- Creator operating system live — apply → 2-tier peer endorsement → admin approval → tier-promotion cron
For every ₹1 we spend to win a user, we get ₹12.50 back.
Three forces compound to land 12.5x by Month 12 — revenue per user climbs as the monetization stack stacks, acquisition cost falls as the creator network carries distribution, and gross margin lifts as AI inference prices drop.
Follow one user from sign-up to year-end.
Acquired through a creator, a campus event, or paid ad.
Blended across the ₹499 sub, ₹199 interview SKU, ₹18K cohorts, and ₹9K mentorship packs.
That's 81% gross margin. AI cost-to-serve drops ~70% over the year as inference prices fall.
The three forces, in detail.
Each is independent. The model still clears 7x LTV:CAC if only two of the three land.
Each user pays us more over time
Same user, more products. They start on the ₹499 subscription. ~9% upgrade to a ₹18K cohort. ~4% buy a ₹9K mentorship pack. We earn more from the same user without spending anything to acquire them again.
Each user costs less to win
Creators bring their existing audience to ScaleUp. As the creator network grows, more new users come from word-of-mouth and creator pull instead of paid ads. Paid acquisition cost drops 34%.
We keep more of every rupee
AI inference prices fall every quarter, and we cache aggressively. Cost of running the AI tutor + interviewer drops from ~₹120/user/mo to ~₹38/user/mo. That falls straight to gross margin.
The platform educational creators actually want to build on.
Hand-picked supply. 52 creators by M12 across three tiers. Equity only for the founding cohort (first 20–30 creators, capped at ~4.5–5%). After that: retainer + their own earnings + performance bonus on paying users converted.
Three components. Retainer is the floor — pays them to commit a content cadence. Their own earnings on YouTube / Instagram / LinkedIn keep flowing — we don’t ask for exclusivity. And a one-time performance bonus pays per 1,000 paying users they bring in their first 90 days — directly tying their upside to actual conversions, not abstract ownership.
Why one-time bonus instead of recurring revenue share? Capped exposure for us, predictable upside for them, no attribution complexity over time, and clean P&L. The bonus rewards the moment that actually matters — a paying user converting through their content.
Senior PMs, founding engineers, domain experts who already have a following on YouTube / Instagram / LinkedIn. ScaleUp is additive — they keep posting on their own channels. We pay cash + (for the founding cohort only) equity + a one-time conversion bonus on the paying users they bring in.
Mid-career operators with teaching chops — turn lived experience into curriculum. Some have audiences, some are building. Strong enough to draw learners, flexible enough to grow on ScaleUp alongside their day job.
Cash-only — no equity. Builds the long-tail catalogue and acts as our talent pool. Top performers graduate to Core retainer + bonus, and exceptional performers may receive equity case-by-case.
Only the first 20–30 Anchor + Core creators receive equity, totalling 4.5–5% of the cap table. After this cohort, every additional Anchor / Core creator earns retainer + their own channel earnings + performance bonus only — no further equity dilution. Exception: a creator who is exceptional on outcome metrics may receive a discretionary equity grant — case-by-case, not policy.
How the creator economics actually work
Retainer secures supply early · performance bonus rewards conversion · equity locks the founding cohort
How we acquire the founding 20–30 creators
We’re hiring creators the way SaaS companies hire founding engineers — outbound, warm intros, audience-bring incentives, and a referral loop. No exclusivity asks.
Outbound to top educational creators on YouTube, Instagram, LinkedIn, and Substack. Warm intros via investors and existing creators. Target 30 named practitioners per tier.
Creators who already have a following keep posting on their own channels. The conversion bonus pays them every time their audience converts to a paying ScaleUp user — directly aligning the creator’s pull with our growth.
A modest bonus for any creator who refers another creator we sign. Keeps the network growing through people who already vouch for the platform — not paid acquisition.
IIT-B + DJ Sanghvi alumni → Rising tier. Already de-risked through our beta testing relationships. Steady supply for Year-2+.
Operator-grade build. Pre-funding.
We are pre-traction, pre-revenue, in closed beta — and the platform is already a working AI-graded outcome machine. Below are four capabilities live on iOS + Android today, built before a single rupee raised. The build itself is the proof.
Tutor mode for in-content questions. Coach mode with weekly / monthly / topic scope. Quick-action chips that route to a quiz, interview, coding drill, or capstone. Replaces eleven fragmented per-feature AI surfaces with one — and is the primary surface every V2 user touches every day.
Phone shows brief + pairing code + QR. Learner opens the laptop, codes in an e2b sandbox under an anti-cheat preflight. Claude Sonnet 4.6 produces a 6-dimension scorecard with evidence_notes — a "Detailed analysis" artifact the learner can share with a recruiter. Voice reflection re-evaluates after.
V2 Home is a plan cockpit — readiness trajectory chart, today's five tasks, drill card, capstone milestone, this-week forecast. A cron at 00:15 IST auto-seeds three personalised quizzes per active user from their weakest topics, before they even open the app.
Three-tier creator model live (Anchor / Core / Rising). Apply flow, two-tier peer endorsement queue, admin approval, content moderation, cost-summary + anchor-drift admin dashboards, weekly tier-promotion cron — all shipped pre-funding. The supply-side engine is ready before the creators land.
A real stack. Not a prompt-wrapped MVP.
Today: a 4-layer stack with a multi-model AI gateway in front of every LLM call. Tomorrow: our own agentic orchestration, domain RAG, and on-device inference — the things that turn this from “a wrapper” into a defensible AI product.
Frontend
Native iOS in Swift. Cross-platform mobile + web in React Native and React + Tailwind. Shared design system across all surfaces.
Backend
Node.js services with BullMQ for background work, Redis for queueing + caching, and S3 for video / asset storage. Deployed on managed cloud, horizontal scale-out by default.
Database
MongoDB as the system of record — flexible document model fits the way our content, profiles, and adaptive paths evolve. Indexes tuned for the read patterns the AI layer needs.
AI Layer (today)
Multi-model gateway routes every request to whichever LLM is best per task — Claude for tutoring & interview, ChatGPT for content generation, Gemini for cheap large-context evaluation. Caching + per-request cost tracking baked in.
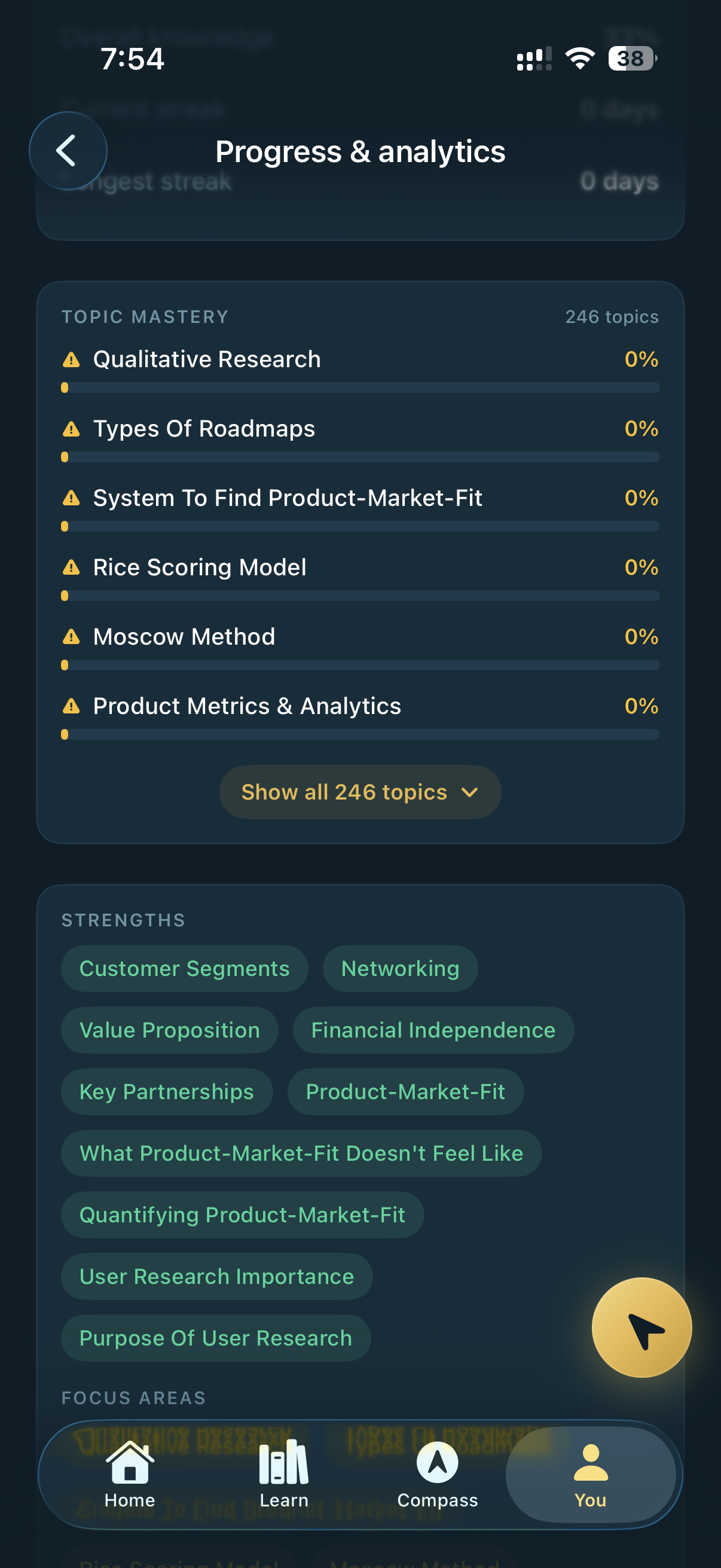
246 topics tracked per learner across the chosen track. Per-topic mastery + auto-detected strength chips. Updated after every quiz, video, AI conversation, drill, and capstone.
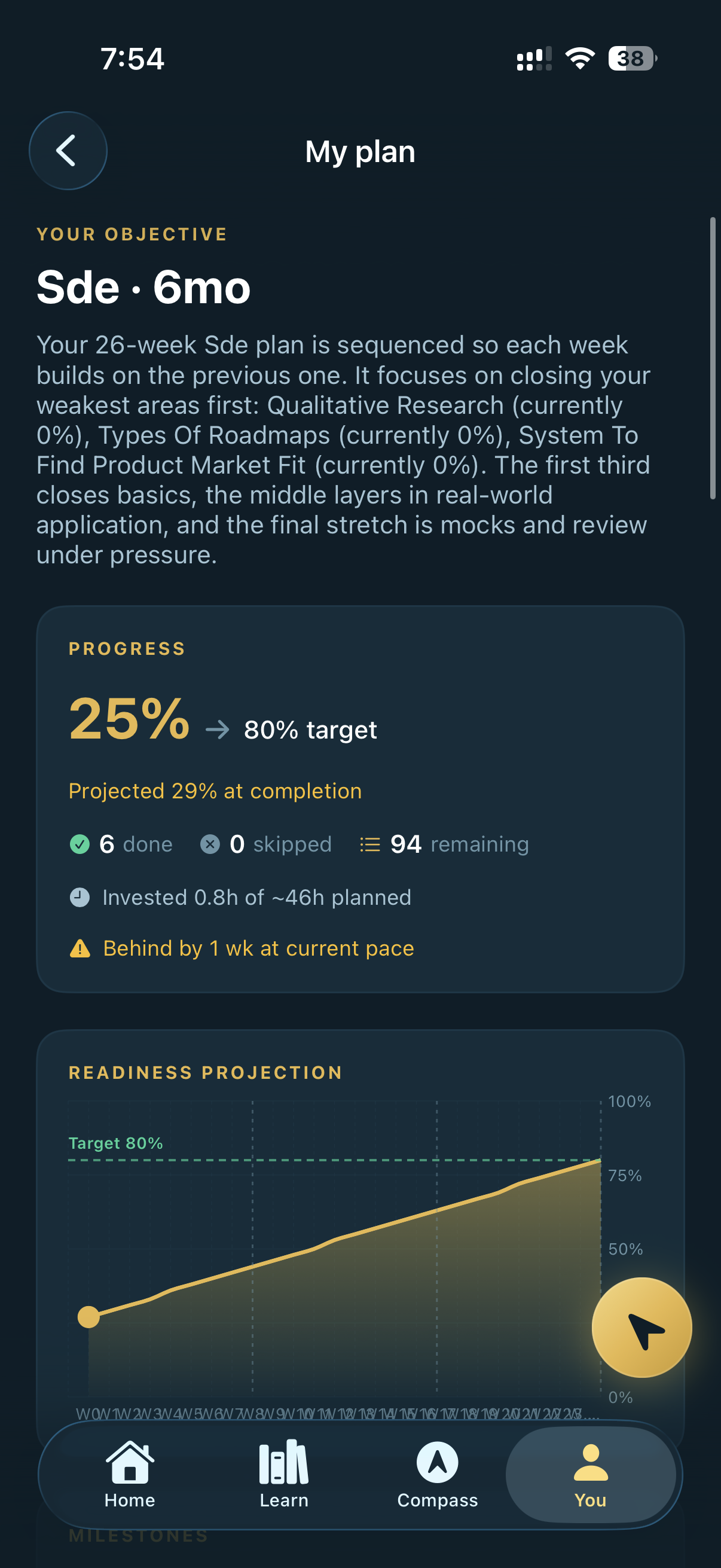
Profile becomes plan — 26 weeks sequenced from your starting profile to your stated objective. Live progress vs. target with a forward readiness projection. Re-routes weekly as the profile changes.
One AI that knows your full context — goal, plan, gaps, history. Replaces eleven fragmented per-feature AI surfaces with a single coach that routes to a quiz, interview, note, or coding drill via natural language or a quick-action chip.
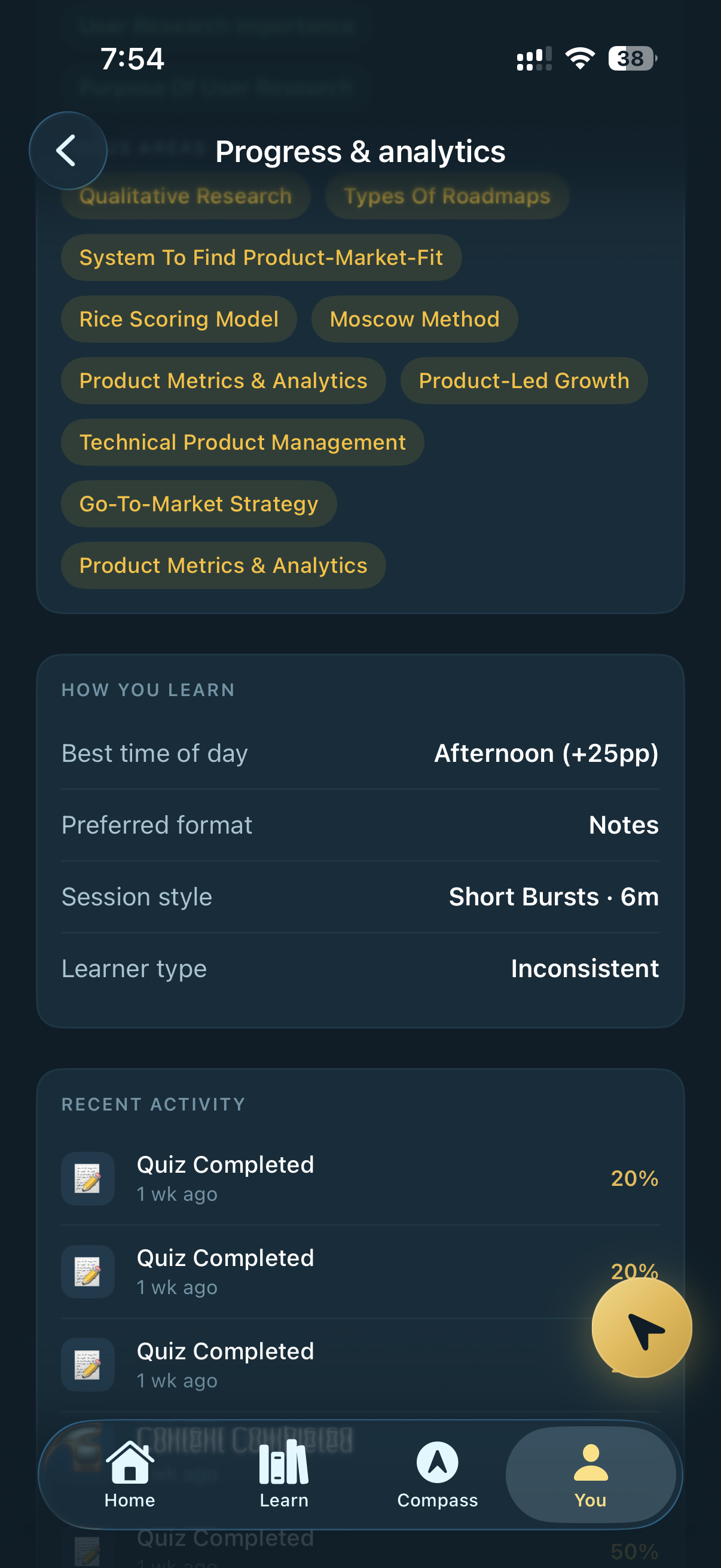
Topic mastery, focus areas, and a "How You Learn" block — best time of day, preferred format, session style, learner type. The platform learns the learner, not just the topic.
Every mock interview voice-graded and scored. Behavioral / placement HR / case study / MBA admissions / placement technical. Per-question rubric + role-tailored model answers. Aggregate scorecard per session, history across attempts.
₹120 → ₹38 per paying user / month over 12 months. Here are the four levers — none of them require a miracle.
₹120/user is what we spend today routing every interaction through a frontier LLM. ₹38 is what we get to once these four levers are in place. We hit any three of them, we’re still under ₹55.
| Lever | Today | M12 target | Why it works |
|---|---|---|---|
| Tokens per active user / month | ~620K | ~430K | Smarter routing — short turns to cheaper models, longer reasoning only when needed. |
| Blended $/1M output tokens | ~$8.40 | ~$3.10 | Public model prices have fallen ~50% in 12 months and are still falling. Our gateway routes to whichever is cheapest per task. |
| Cache hit rate (semantic + prompt) | ~22% | ~55% | Most learner questions on the same concept are near-duplicates. Semantic + prompt caching cuts repeat inference cost dramatically. |
| On-device inference (CoreML) | 0% | ~25% | Move grading, classification, and short-turn tutor responses to on-device once iOS app ships in M3. |
On-device inference (CoreML)
Move quiz-grading, intent-detection, and basic AI-tutor turns to CoreML on iOS. Cuts cost-to-serve to near-zero on those paths and gives sub-100ms responses even offline.
Our own Agentic AI orchestration
A dedicated agentic layer that owns multi-step learner flows — diagnostic → plan generation → re-routing → outcome scoring. Today this is glued together; the build makes it a first-class system.
Domain RAG + SLM/LLM combo
Retrieval-augmented generation grounded in our own competency graph and content corpus. Small fine-tuned model handles 80% of conversational turns; we route to a frontier LLM only for the hard 20%.
Knowledge graph + behaviour data
After 12 months of usage, our concept graph + per-user behaviour data is a structural moat. Library platforms can’t replay 2 years of adaptive routing decisions.
Multi-model AI gateway
We don’t depend on one model. Internal gateway routes to whichever is cheapest/best per task. As prices drop, we drop with them — never locked into one provider.
We measure what library platforms refuse to.
Library platforms count video views and certificates. We grade the actual work. Below are the four primitives we measure today — built and operational before a single rupee raised. Closed-beta cohort data publishes at end of beta.
Mechanisms in production. Not promises of measurement.
Coursera reports completion rates. Scaler reports placement counts. ScaleUp reports the readiness movement — AI-graded on the actual work, per concept, per role, per learner.
The honest strategic picture.
Where we have a real edge, where we’re thin, where the wind is at our back, and what could go wrong. Investors deserve all four.
Strengths
- Adaptive Knowledge ProfileNo competitor in India has this. Library platforms can’t retrofit it without re-architecting their entire content model.
- Practitioner creator networkFounding cohort of 20–30 Anchor + Core creators with vesting equity (~4.5–5% capped). Retainer + own-channel earnings + one-time performance bonus on paying users converted. Hard to replicate — we’re paying real money for the best PMs/SDEs in India.
- AI cost-curve advantageOur entire margin model bets on inference prices falling — the only direction they’ve gone in 24 months. GM 68% → 81% is the lift.
- Outcome-first positioningCoursera reports 6–10% completion. Scaler reports placement counts. We report the score that actually moves: “+34 readiness points” means a learner went from ‘rejected at resume screen’ to ‘getting first-round interviews at companies in their target band’ — in 4 weeks. No library platform can make that claim.
Weaknesses
- Pre-revenue, small team2 full-time founders today. Engineering, content, and creator-ops scale only post-funding. Execution risk is real — mitigated by hiring plan in M1–M3.
- Brand equity from zeroNo existing learner mindshare vs Scaler/upGrad. We earn the first 1,500 paying users through creator pull, not paid funnel — deliberate but slower.
- Single-geography concentrationIndia-only by design for first 18 months. Dependent on Indian creator economy and edtech ARPU dynamics. Mitigated by sheer TAM (50M+ aspirants).
Opportunities
- Library platforms are mid-cycleScaler/upGrad have ARR but flat retention. They can’t pivot to outcome-first without cannibalizing their library. We’re the only outcome-native bet.
- AI tutor economics flip the model24-month inference cost decline turns a ₹120/user line into ₹38/user. Every quarter we wait, the model gets stronger.
- Creator economy maturing in IndiaTop PMs/SDEs are actively monetizing. We’re the first platform offering them retainer + performance bonus + (for the founding cohort) equity + audience tooling — without asking for exclusivity.
- CompExam adjacent (M3 launch)GATE/CAT/UPSC — same outcome-first thesis, 5x larger TAM. We launch this vertical at M3 once core platform is proven.
Threats
- Big-tech distributionGoogle/Microsoft could ship a generic AI tutor with India SKU. Mitigated: education needs vertical depth + creator credibility we have, they don’t.
- Library incumbent counter-attackScaler/upGrad bolt on an “AI Coach” module. Mitigated: they’d have to abandon library positioning. They won’t — it’s their ARR.
- Edtech sentiment in capital marketsBYJU’s overhang affects edtech multiples. Mitigated: outcome-first + AI margins put us in a different category narrative — closer to vertical SaaS than ed.
Three curves cross at this exact window.
The AI cost curve, the collapse of trust in library platforms, and the maturity of India’s practitioner-creator economy. None of these were true in 2022. All of them are true now.
AI cost curve — down and to the right
Inference cost for frontier-class models has dropped ~85% in 24 months (GPT-4 → Claude Sonnet 4.7 → Gemini Flash). For the first time, we can serve a 1:1 AI tutor at ₹38/user/month and still make 81% gross margin. 18 months ago this product was financially impossible.
Trust vacuum in Indian edtech
BYJU’s collapse, UpGrad re-pricing, Unacademy layoffs — the library era is in active retreat. Learners are skeptical of any platform that pitches “hours of content.” The category is wide open for an outcome-first contender that can prove movement.
Creator economy maturity
Top PMs/SDEs in India are now monetizing directly (Maven, Topmate, Substack). They’re ready for an equity-bearing platform that handles audience, billing, and pedagogy. This wasn’t true in 2022 — they were still inside companies.
₹6 Cr on a SAFE at a ₹30 Cr post-money cap.
On this page: the deal terms, the cap-table walk from 50/50 today through post pre-seed, term-by-term justifications, and the Seed-round preview with the milestones we hit before raising it.
And the part we’re proudest of — every input below is live-modelable. Move any slider, the whole cap table re-prices in real time.
Today → pre-money planned → post pre-seed
Cap table is 50/50 today between the two co-founders. ESOP + creator pool are carved out of the pre-money before the round. The new investors take 20.0% of the post-round cap table at the values above.
13-month runway. Funds 5 verticals already-live + CompExam launch + creator network bootstrap + path to 1,500 paying users at ₹11.7L MRR. Sized for speed, not survival.
Indian AI-edtech trades at 18–28x forward ARR at Seed. Our M12 ARR run-rate of ₹4.2 Cr would imply ₹75–120 Cr at Seed — the ₹30 Cr pre-seed cap is well below that floor. Beta validation (300+ users) removes the 'idea-stage' discount.
Standard YC SAFE discount. Triggers if Seed prices below the cap. Protects the early backer for taking pre-revenue risk before the M12 numbers exist.
Optional dilution floor: SAFE never converts below this implied valuation. Protects against Seed pricing markdowns from market conditions outside our control. Not standard, but we're including it to give early backers downside comfort.
Pre-money carve-out for M1–M12 hires (3 engineers, 1 data scientist, marketing + design + ops). Standard for pre-seed-funded teams scaling from 2 → 10 in 12 months.
Founding cohort only — first 20–30 creators (Anchor + Core). After this cohort, every additional creator earns retainer + own-channel earnings + performance bonus only. Zero further equity dilution from creators.